Jupyter and Minio 1
Getting Spark on k8s Jupyter writing to minio
A quick info dump here.
My setup
I have a k8s cluster running on my LAN, which I do not expose to the outside world at all. I have already figured out (and deployed the necessary components for):
- Running k8s on my homelab, and being able to deploy to it (I use k3s on two beefy VMs running on two separate Windows Server instances on bare metal– running on commodity hardware).
- A solution for creating PVs and assigning PVCs to the projects (We use smb to our NAS, and the NAS and the cluster nodes are hard-wired to the same switch).
- A wildcard DNS entry on the intranet that points to the k8s control plane (rpi4), which is running Traefik for http routing based on k8s ingress.
- A docker registry running on the homelab with a process already set up to be able to push local images to it, and the k8s nodes to be able to pull images from it
Minio
Minio is a self-hostable object store that is S3-compatible. There are a ton of features, but a “single-drive, single-node” deployment on my homelab is absolutely more than enough and extremely easy to set up.
apiVersion: v1
kind: PersistentVolume
metadata:
name: minio-data-pv
spec:
persistentVolumeReclaimPolicy: Retain
accessModes:
- ReadWriteMany
# Do the PV that works for your setup
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: minio-data-pvc
spec:
accessModes:
- ReadWriteMany
volumeName: minio-data-pv
---
apiVersion: v1
kind: Service
metadata:
name: minio
spec:
ports:
- name: s3-api
port: 9000
protocol: TCP
- name: s3-web
port: 9001
protocol: TCP
selector:
app: minio
type: ClusterIP
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: minioss
spec:
replicas: 1
selector:
matchLabels:
app: minio
serviceName: minio-service
template:
metadata:
labels:
app: minio
spec:
containers:
- command:
- /bin/sh
- -ce
- minio server /mnt/data --address :9000 --console-address :9001
env:
- name: MINIO_ROOT_USER
value: some_username
- name: MINIO_ROOT_PASSWORD
value: some_password
- name: MINIO_VOLUMES
value: /mnt/data
- name: MINIO_API_SELECT_PARQUET
value: "on"
- name: MINIO_BROWSER
value: "on"
- name: MINIO_PROMETHEUS_AUTH_TYPE
value: public
image: quay.io/minio/minio:latest
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 10
tcpSocket:
port: 9000
timeoutSeconds: 3
name: minio-container
ports:
- containerPort: 9000
- containerPort: 9001
readinessProbe:
initialDelaySeconds: 30
periodSeconds: 10
tcpSocket:
port: 9000
timeoutSeconds: 3
volumeMounts:
- mountPath: /mnt/data
name: data
nodeSelector:
kubernetes.io/arch: amd64 # If you have arm nodes
volumes:
- name: data
persistentVolumeClaim:
claimName: minio-data-pvc
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
labels:
app: minio
name: minio-ingress
spec:
ingressClassName: traefik #Do your own ingress here that works for you
rules:
- host: s3.example.com
http:
paths:
- backend:
service:
name: minio
port:
number: 9000
path: /
pathType: Prefix
- host: s3web.example.com
http:
paths:
- backend:
service:
name: minio
port:
number: 9001
path: /
pathType: Prefix
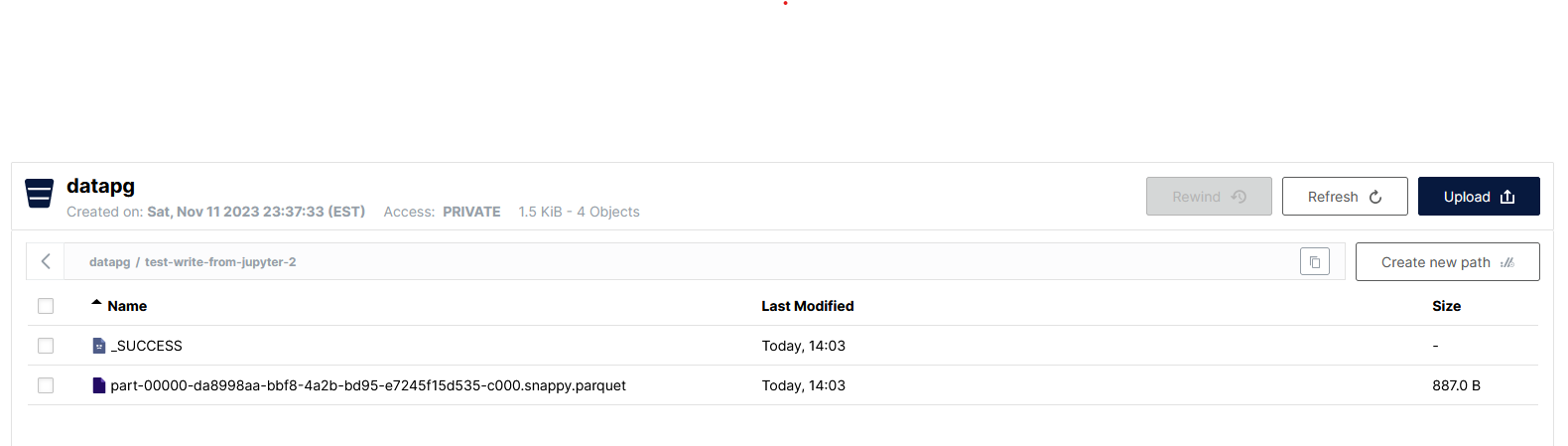
Then you can log into s3web.example.com with your root user and password.
Log in, create a user with readwrite permissions, and get (and copy) your access key and secret key. Create a bucket for your data.
Jupyter lab
If you already have a running Jupyter lab setup, use it.
If you don’t, but all you’re going to use is Scala/Spark, then I recommend using the almond/almond docker image.
I personally wrote a dockerfile that combines almond with jupyter/datascience-notebook, and add in some other things such as poetry and updating pandas.
I use the Attach to Visual Studio Code option on the jupyter lab pod, when looking at it in the kubernetes VSC extension.
Here is the code I used to generate a test parquet file:
import $ivy.`org.apache.spark::spark-sql:3.3.0`
import $ivy.`sh.almond::ammonite-spark:0.13.9`
import $ivy.`org.apache.hadoop:hadoop-aws:3.3.6`
import $ivy.`org.apache.hadoop:hadoop-common:3.3.6`
import $ivy.`org.apache.hadoop:hadoop-client:3.3.6`
import $ivy.`com.amazonaws:aws-java-sdk-bundle:1.12.367`
import org.apache.log4j.{Level, Logger}
Logger.getLogger("org").setLevel(Level.OFF)
import org.apache.spark.sql._
val spark = {
NotebookSparkSession.builder()
.master("local[*]")
.config("spark.hadoop.fs.s3a.access.key", "minio-access-key")
.config("spark.hadoop.fs.s3a.secret.key", "minio-secret-key")
.config("spark.hadoop.fs.s3a.endpoint", "https://s3.example.com")
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
.config("spark.hadoop.fs.s3a.path.style.access", "true")
.getOrCreate()
}
import spark.implicits._
val data = Seq((1, 2, 3), (3, 4, 5), (5, 6, 9)).toDF("a", "b", "c")
data.write.parquet("s3a://datapg/test-write-from-jupyter/")